TFLite Micro on RISC-V Out-of-Order Core with Custom Instructions
We have accelerated inference on Google’s TensorFlow Lite for Microcontrollers (TFLite Micro) by adding SIMD instructions as custom instructions to NaxRiscv, a RISC-V out-of-order core.
In the related article TensorFlow Lite for Microcontrollers on RISC-V Out-of-Order Core, we reported that we successfully ran TFLite Micro, the bare-metal version of TensorFlow Lite, on an FPGA board with NaxRiscv. This article is a continuation of that.
See related articles on NaxRiscv here.
NaxRiscv
NaxRiscv is an out-of-order execution superscalar RISC-V core. NaxRiscv is integrated into LiteX, an SoC builder. For an overview of NaxRiscv, see the related article Benchmarks on RISC-V Out-of-Order Simulator.
NaxRiscv Custom Instructions
NaxRiscv is written in a hardware description language called SpinalHDL, and you can add custom instructions using SpinalHDL. Custom instruction in the NaxRiscv documentation provides an example of adding SimdAdd as a custom instruction.
This time we created a SimdMulPlugin.scala file to add SIMD instructions (mul + reduction sum and variants) as custom instructions, referring to the SimdAdd example above. NaxRiscv can add functions by plug-ins, and MUL and DIV instructions are implemented as MulPlugin and DivPlugin respectively.
Also, we added SimdMulPlugin to ALU0 and ALU1 so that custom SIMD instructions can be executed on both ALU0 and ALU1, and created gateware for Digilent’s FPGA board, Nexys Video.
TFLite Micro on NaxRiscv with SimdMul
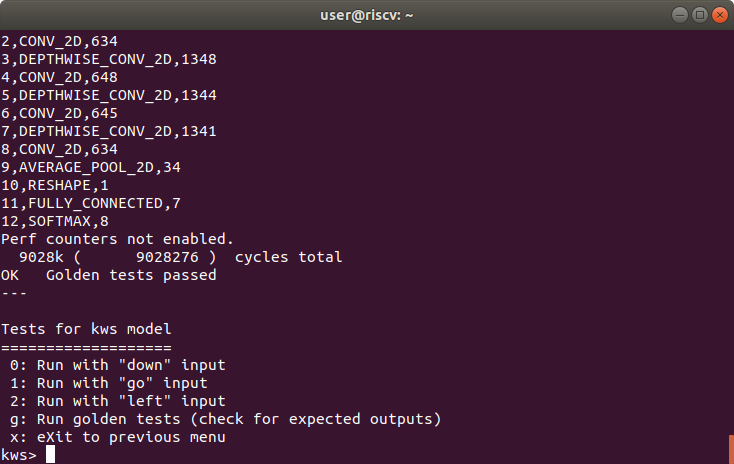
Result of golden tests for Keyword Spotting model
We loaded the above gateware onto an FPGA board, Nexys Video, and ran TFLite Micro’s Keyword Spotting, Person Detection and MobileNetV2 models.
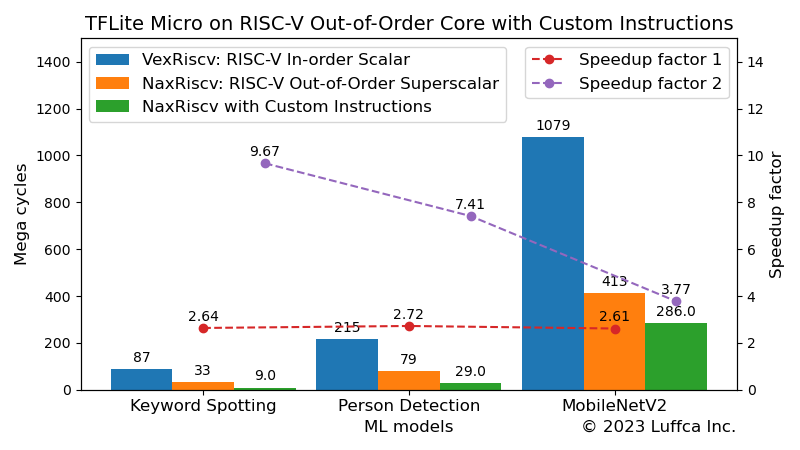
The featured image and the table below show the results compared to VexRiscv, an in-order execution scalar RISC-V core.
| ML models | Mega cycles | Speedup factor |
|
|---|---|---|---|
| VexRiscv | NaxRiscv w/ SimdMul |
||
| Keyword Spotting | 87 | 9.0 | 9.67 |
| Person Detection | 215 | 29 | 7.41 |
| MobileNetV2 | 1079 | 286 | 3.77 |
The Keyword Spotting model has an inference cycle count of 9.0M, and the speedup compared to VexRiscv is about 9.7 times. The number of cycles of the ML processor in Building an ML Processor using CFU Playground (Part 2) is 9.8M, so it has the same performance.
In addition, the number of cycles for inference of the Person Detection model is 29M, and the speedup compared to VexRiscv is about 7.4 times. The number of cycles of the processor that speeds up the matrix multiplication operation introduced in Applying the Tiny Matrix Extension to ML Inference is 29.3M, so it also has the same performance.
Summary
By adding SIMD instructions as custom instructions to NaxRiscv, an out-of-order execution superscalar RISC-V core, we have accelerated TFLite Micro’s Keyword Spotting model inference by approximately 9.7 times compared to VexRiscv, an in-order execution scalar RISC-V core.