Running Auto-Vectorized Program on RISC-V Vector RTL Simulator
In order to utilize the RISC-V “V” vector extension (RVV), we have built programs using LLVM/Clang automatic vectorization and ran them on RTL simulator of Vicuna, which complies with the RVV specification v1.0.
Click here for related articles.
- Running Auto-Vectorized Program on RISC-V Vector RTL Simulator (this article)
- Matrix Multiplication based on the RISC-V Vector Extension
- 1×1 Convolution based on the RISC-V Vector Extension
Vicuna – a RISC-V Zve32x Vector Coprocessor
Vicuna is an open source 32-bit integer vector coprocessor written in SystemVerilog that implements version 1.0 of the RVV specification.
More precisely, Vicuna complies with the Zve32x extension (excluding divide instructions at the time of writing), a variant of the V extension aimed at embedded processors. The extension supports vector element widths of 8, 16, and 32 bits and does not require 64-bit elements or floating point support.
Since Vicuna is a coprocessor, it requires a main processor. At the time of writing, OpenHW Group’s CV32E40X or a modified version of lowRISC’s Ibex is available as the main processor.
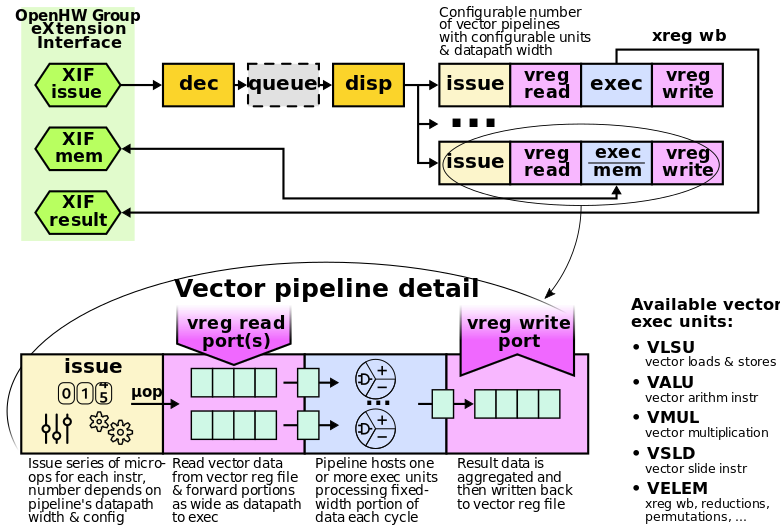
The figure below quoted from the Vicuna repository gives an overview of Vicuna.
RISC-V Vector RTL Simulator
This time, we have created RTL simulators using the default Verilator.
According to README.md in Vicuna’s test directory, you can create an RTL simulator using Vivado’s xsim or Questasim.
Automatic Vectorization for RVV in LLVM/Clang
In order to utilize automatic vectorization for RVV, add two or more -O and -mllvm --riscv-v-vector-bits-min= options to Clang.
To generate assembly code for Vicuna of VLEN=128 from matmul_vec.c, run the following command.
clang --target=riscv32 -march=rv32imzve32x -mabi=ilp32 \ -O2 -mllvm --riscv-v-vector-bits-min=128 \ -S matmul_vec.c
Below is the code of matmul_vec.c.
#include <stdint.h>
void matmul_vec(int n, int16_t* a, int16_t* b, int32_t* c) {
int i, j, k;
for (i = 0; i < n; ++i) {
for (j = 0; j < n; ++j) {
for (k = 0; k < n; ++k) {
c[i * n + j] += (int32_t)a[i * n + k] * (int32_t)b[k * n + j];
}
}
}
}
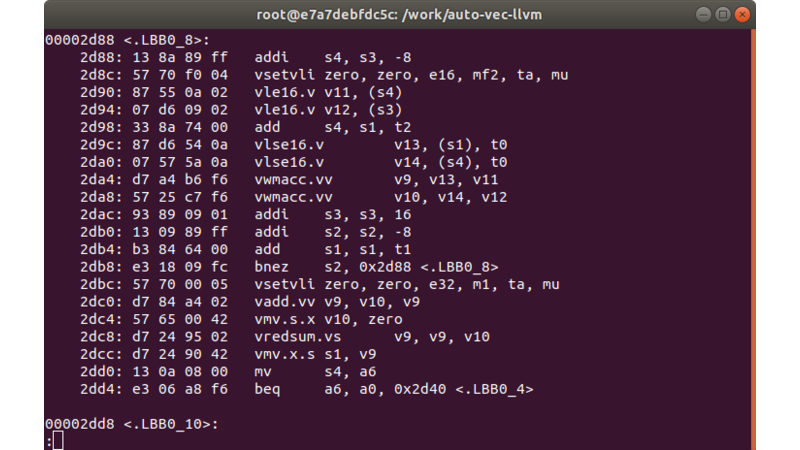
The following code is an excerpt of the generated matmul_vec.s. Also, the featured image is an excerpt from the llvm-objdump of the built program.
...
.LBB0_8:
addi s4, s3, -8
vsetvli zero, zero, e16, mf2, ta, mu
vle16.v v11, (s4)
vle16.v v12, (s3)
add s4, s1, t2
vlse16.v v13, (s1), t0
vlse16.v v14, (s4), t0
vwmacc.vv v9, v13, v11
vwmacc.vv v10, v14, v12
addi s3, s3, 16
addi s2, s2, -8
add s1, s1, t1
bnez s2, .LBB0_8
vsetvli zero, zero, e32, m1, ta, mu
vadd.vv v9, v10, v9
vmv.s.x v10, zero
vredsum.vs v9, v9, v10
vmv.x.s s1, v9
mv s4, a6
beq a6, a0, .LBB0_4
.LBB0_10:
...
Running Auto-Vectorized Program on Simulator
The following shows the console output when running make run.
$ make run ../Vvproc_top_128_32 test_matmul.txt 32 262144 1 1 /dev/null A, B: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 C_normal: 90 100 110 120 202 228 254 280 314 356 398 440 426 484 542 600 C_vec: 90 100 110 120 202 228 254 280 314 356 398 440 426 484 542 600 Passed. matmul_normal: 1049 cycles matmul_vec: 1251 cycles
Summary
In order to utilize the RVV, we have built programs using LLVM/Clang automatic vectorization and ran them on RTL simulator of Vicuna, which is compliant with the Zve32x extension of the RVV specification v1.0.