Running Auto-Vectorized Program on RISC-V Vector RTL Simulator
Luffcaでは、RISC-V “V” vector extension(RVV)を利用するため、LLVM/Clangの自動ベクトル化を用いてプログラムをビルドし、RVV仕様v1.0に準拠するVicunaのRTLシミュレータ上で実行しました。
関連記事は、こちら。
-
- Running Auto-Vectorized Program on RISC-V Vector RTL Simulator(本記事)
- Matrix Multiplication based on the RISC-V Vector Extension
- 1×1 Convolution based on the RISC-V Vector Extension
Vicuna – a RISC-V Zve32x Vector Coprocessor
Vicunaは、SystemVerilogで記述されたオープンソースの32ビット整数ベクトルコプロセッサで、RVV仕様のバージョン1.0を実装しています。
より正確には、Vicunaは、組み込みプロセッサを対象としたベクトル拡張のバリアントのZve32x拡張(執筆時点では除算命令を除く)に準拠しています。この拡張は、ベクトル要素幅の8、16および32ビットをサポートし、64ビット要素や浮動小数点のサポートを必要としません。
なお、Vicunaはコプロセッサなので、メインプロセッサが必要となります。執筆時点において、メインプロセッサとしてOpenHW GroupのCV32E40XまたはlowRISCのIbexの変更版を利用できます。
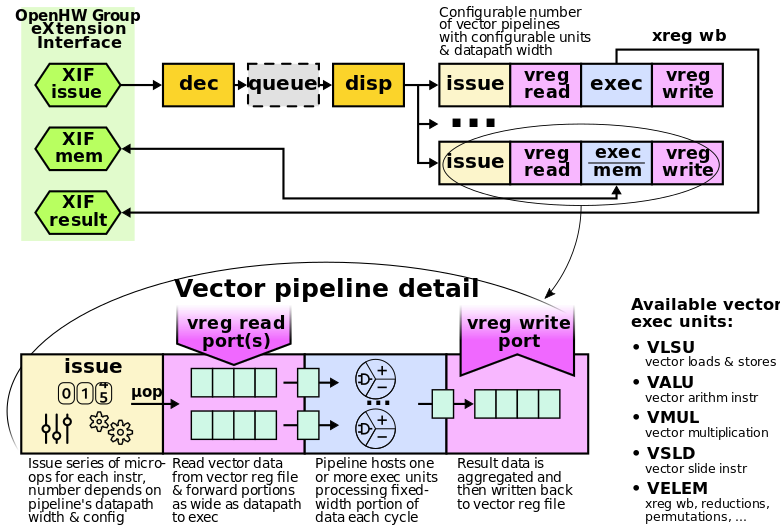
Vicunaリポジトリから引用した下図が、Vicunaの概要を示しています。
RISC-V Vector RTL Simulator
今回は、デフォルトのVerilatorを用いてRTLシミュレータを作成しました。
VicunaのtestディレクトリのREADME.mdによると、VivadoのxsimまたはQuestasimを用いてRTLシミュレータを作成することも出来るようです。
Automatic Vectorization for RVV in LLVM/Clang
RVVの自動ベクトル化を利用するために、Clangに2以上の-Oオプションと-mllvm --riscv-v-vector-bits-min=オプションを追加します。
matmul_vec.cからVLEN=128のVicuna用アセンブリコードを生成する場合、以下のコマンドを実行します。
clang --target=riscv32 -march=rv32imzve32x -mabi=ilp32 \ -O2 -mllvm --riscv-v-vector-bits-min=128 \ -S matmul_vec.c
以下がmatmul_vec.cのコードです。
#include <stdint.h>
void matmul_vec(int n, int16_t* a, int16_t* b, int32_t* c) {
int i, j, k;
for (i = 0; i < n; ++i) {
for (j = 0; j < n; ++j) {
for (k = 0; k < n; ++k) {
c[i * n + j] += (int32_t)a[i * n + k] * (int32_t)b[k * n + j];
}
}
}
}
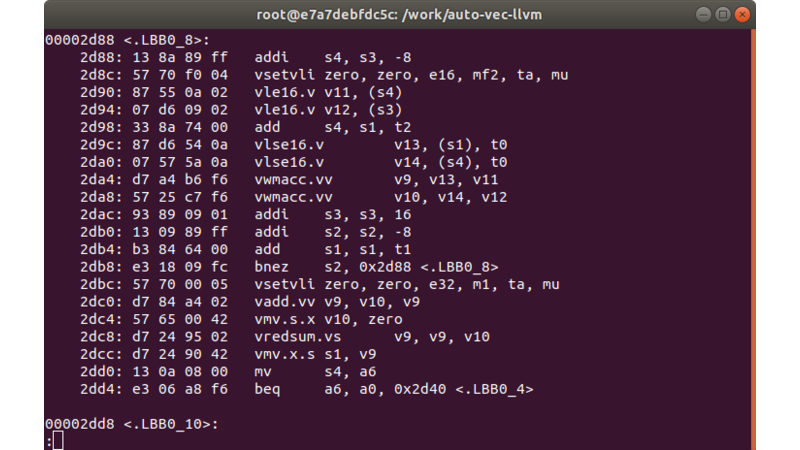
以下のコードは、生成されたmatmul_vec.sの抜粋です。また、アイキャッチ画像は、ビルドしたプログラムのllvm-objdumpからの抜粋です。
...
.LBB0_8:
addi s4, s3, -8
vsetvli zero, zero, e16, mf2, ta, mu
vle16.v v11, (s4)
vle16.v v12, (s3)
add s4, s1, t2
vlse16.v v13, (s1), t0
vlse16.v v14, (s4), t0
vwmacc.vv v9, v13, v11
vwmacc.vv v10, v14, v12
addi s3, s3, 16
addi s2, s2, -8
add s1, s1, t1
bnez s2, .LBB0_8
vsetvli zero, zero, e32, m1, ta, mu
vadd.vv v9, v10, v9
vmv.s.x v10, zero
vredsum.vs v9, v9, v10
vmv.x.s s1, v9
mv s4, a6
beq a6, a0, .LBB0_4
.LBB0_10:
...
Running Auto-Vectorized Program on Simulator
以下は、make runを実行したときのコンソール出力を示しています。
$ make run ../Vvproc_top_128_32 test_matmul.txt 32 262144 1 1 /dev/null A, B: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 C_normal: 90 100 110 120 202 228 254 280 314 356 398 440 426 484 542 600 C_vec: 90 100 110 120 202 228 254 280 314 356 398 440 426 484 542 600 Passed. matmul_normal: 1049 cycles matmul_vec: 1251 cycles
まとめ
Luffcaでは、RISC-Vベクトル拡張(RVV)を利用するため、LLVM/Clangの自動ベクトル化を用いてプログラムをビルドし、RVV仕様v1.0のZve32x拡張に準拠するVicunaのRTLシミュレータ上で実行しました。