Building an ML Processor using CFU Playground (Part 3)
Luffcaでは、CFU Playgroundを用いて、Arty A7-35T上にML(Machine Learning)プロセッサを作成しました。パート3では、MobileNetV2モデルの推論を5.5倍高速化しました。
なお、CFUはCustom Function Unitの略語であり、LiteX-VexRiscvにおいてRISC-Vのカスタム命令用ハードウェアを追加する仕組みです。
関連記事は、こちら。
- パート1: Person Detection int8モデル
- パート2: Keyword Spottingモデル
- パート3: MobileNetV2モデル(本記事)
CFU Playground
CFU Playgroundは、GoogleのTFLM(TensorFlow Lite for Microcontrollers, tflite-micro)のMLモデルを高速化するために、ハードウェア(実際には、FPGAのゲートウェア)とソフトウェアをチューニングするためのフレームワークです。
詳細は、パート1の記事をご覧ください。
MobileNetV2
MobileNetV2は、軽量モデルとして有名なMobileNetV1の後継モデルです。MobileNetV1のdepthwise separable convolutionを踏襲しながら、inverted residuals and linear bottlenecksという構造を取り入れたモデルです。
arxivの論文から引用した下図は、MobileNetV2のinverted residual blockを示しています。
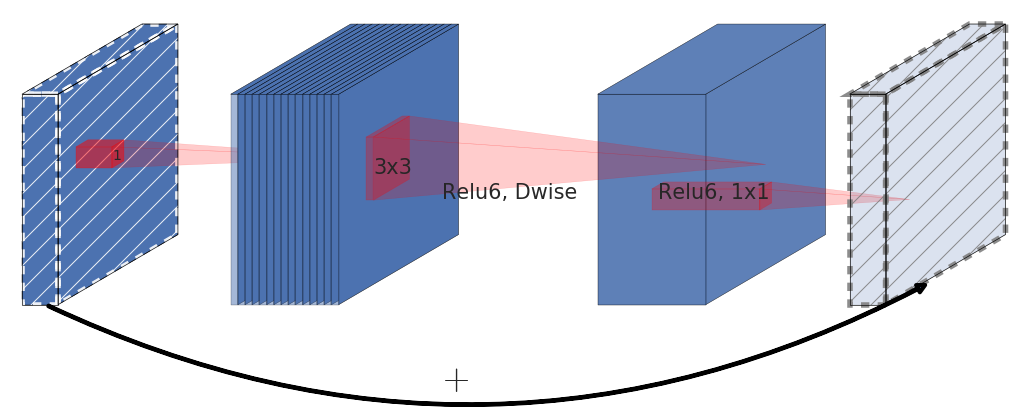
MobileNetV2の詳細は、arxivの論文をご覧ください。
multimodel_accel project
Result of golden tests for MobileNetV2 model
multimodel_accelプロジェクトは、CFU Playgroundのほとんどのプロジェクトが一つのMLモデルに限定して高速化するモデル特化を行っているのに対し、複数のMLモデルを高速化することを目標とする社内プロジェクトです。
上のコンソール画像に示すように、CFU PlaygroundにおいてMobileNetV2はmnv2モデルと呼ばれています。
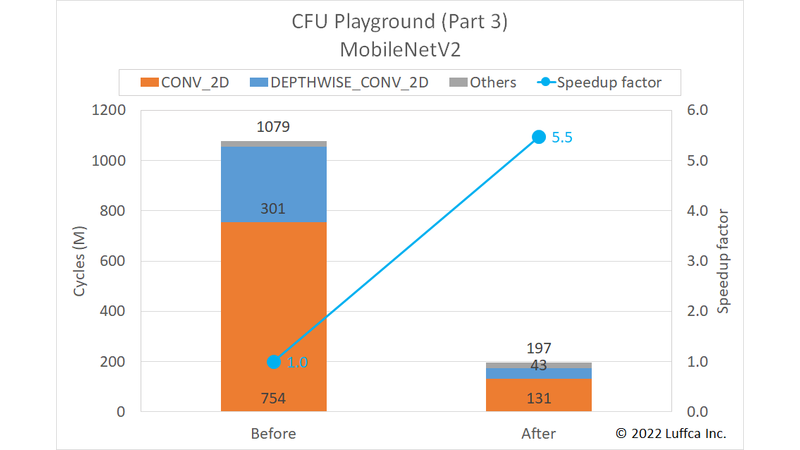
先に結果を紹介すると、アイキャッチ画像と下の表に示すようにmnv2モデルの全サイクル数が1079Mから197Mに減少し、5.5倍の高速化を達成しました。
なお、私達のプロジェクトは、mnv2モデルの全サイクル数を397.5Mに高速化しているCFU Playgroundのmnv2_firstプロジェクトよりも更に2倍高速です。
| MobileNetV2 | Cycles | Speedup factor |
|
|---|---|---|---|
| Before | After | ||
CONV_2D |
754M | 131M | 5.8 |
DEPTHWISE_CONV_2D |
301M | 43M | 7.0 |
| Others | 24M | 23M | 1.0 |
| Total | 1079M | 197M | 5.5 |
なお、複数のMLモデルの高速化を目標にしたmultimodel_accelプロジェクトなので、パート1のPerson Detection int8(以下pdti8)モデルは、48Mから38.4Mに高速化し、パート2のKeyword Spotting(以下kws)モデルは、15.7Mから9.8Mに高速化しています。
Software Specialization & CFU Optimization
multimodel_accelプロジェクトでは、mnv2モデルの他にpdti8モデルとkwsモデルに適用できるように特化・最適化した1×1 convolution(以下1x1_conv)とdepthwise convolution(以下dw_conv)を使用しています。
パート3では、パート1とパート2において1x1_convよりもspeedup factorが小さいdw_convの改良を行いました。具体的には、パート1でCFUに対応していたdw_convを、SIMD(single instruction, multiple data)にも対応させることによって高速化を実現しました。このため、ゲートウェアとソフトウェアの両方を変更しています。
また、他の層の高速化に伴い1x1_convではない最初の2D convolutionの処理時間の比率が高くなってきたため、専用のカーネルを追加しています。
まとめ
Luffcaでは、CFU Playgroundを用いて、Arty A7-35T上にMLプロセッサを作成しました。作成したMLプロセッサは、MobileNetV2の推論を5.5倍高速化し、197Mサイクルで実行できます。