Applying the Tiny Matrix Extension to ML Inference
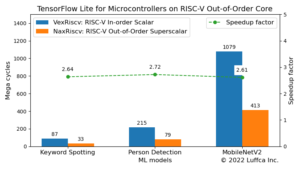
Luffcaでは、省リソースで行列積演算を高速化するプロセッサを用いて、ML(Machine Learning)モデルの推論を高速化しました。具体的には、Tiny Matrix Extensionを備えたRISC-Vプロセッサを用いて、TensorFlow Lite for Microcontrollers(以下、TFLite Micro)のPerson Detectionモデルの推論を7.4倍高速化しました。
関連記事は、こちら。
- Building an ML Processor using CFU Playground (Part 1)
- Tiny Matrix Extension using RISC-V Custom Instructions
- Applying the Tiny Matrix Extension to ML Inference(本記事)
Tiny Matrix Extension
関連記事のTiny Matrix Extension using RISC-V Custom Instructionsで紹介したTiny Matrix Extensionは、RISC-Vのカスタム命令を用いて行列積演算を省リソースで高速化するカスタム拡張です。
Tiny Matrix Extensionの詳細は、関連記事をご覧ください。
Person Detection Model
関連記事のBuilding an ML Processor using CFU Playground (Part 1)で紹介したTFLite MicroのPerson Detectionモデルは、各14層のCONV_2DとDEPTHWISE_CONV_2Dと、各1層のAVERAGE_POOL_2D、RESHAPE、SOFTMAXの合計31層のMLモデルです。
GoogleのCFU Playgroundと関連記事の社内プロジェクトにおいて、全サイクル数はそれぞれ86Mと38.4Mに減少しています。
Applying the Tiny Matrix Extension to Person Detection Model
Result of golden tests for Person Detection model
Tiny Matrix ExtensionをTFLite MicroのMLモデルに適用するにあたり、FPGAボード Arty A7-35T用ゲートウェアに、以下の式のinput_offsetに対応する変更を行いました。
acc += (input_val + input_offset) * filter_val
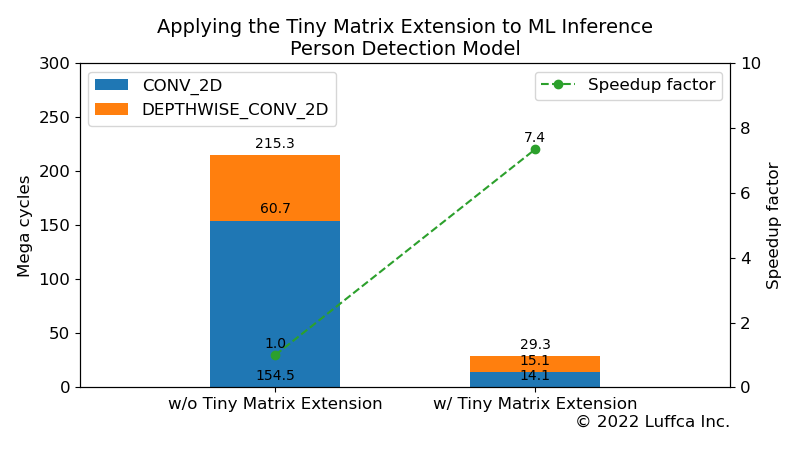
その結果は、アイキャッチ画像と下の表に示すようにPerson Detectionモデルの全サイクル数が215.3Mから29.3Mに減少し、7.4倍の高速化を達成しました。
GoogleのCFU Playgroundの86Mとの比較では2.9倍、関連記事の社内プロジェクトの38.4Mとの比較でも1.3倍高速化しています。
| Person Detection Model |
Cycles | Speedup factor |
|
|---|---|---|---|
| w/o Tiny Matrix Extension |
w/ Tiny Matrix Extension |
||
CONV_2D |
154.5M | 14.1M | 10.9 |
DEPTHWISE_ |
60.7M | 15.1M | 4.0 |
| Total | 215.3M | 29.3M | 7.4 |
まとめ
Luffcaでは、行列積演算を省リソースで高速化するTiny Matrix Extensionを備えたRISC-Vプロセッサを用いて、TFLite MicroのPerson Detectionモデルの推論を7.4倍高速化しました。