OpenMP on FPGA with RISC-V Multi-Core Processor
Luffcaでは、RISC-VマルチコアプロセッサをFPGAボードに実装し、OpenMPを用いた行列積カーネルの性能を評価しました。
関連記事は、こちら。
- Matrix Multiplication based on the RISC-V Vector Extension
- Tiny Matrix Extension using RISC-V Custom Instructions
- OpenMP on FPGA with RISC-V Multi-Core Processor(本記事)
OpenMP
OpenMP(Open Multi-Processing)は、多くのプラットフォーム、命令セット アーキテクチャ、およびオペレーティングシステムにおいて、C、C++、およびFortranの共有メモリ・マルチプロセッシング・プログラミングをサポートするAPI(application programming interface)です。
Matrix Multiplication
関連記事のMatrix Multiplication based on the RISC-V Vector ExtensionとTiny Matrix Extension using RISC-V Custom Instructionsでは、それぞれRISC-Vベクトル拡張とRISC-Vカスタム命令を用いて行列積カーネルを高速化しました。この記事では、OpenMPを用いて行列積カーネルを高速化します。
行列積カーネルは、M × Kの行列AとK × Nの行列Bから、その積であるM × Nの行列Cを計算します。リファレンスカーネルimatmul_refのコードは、以下のようになります。
// C = AB with A = [M x K], B = [K x N], C = [M x N]
void imatmul_ref(const int M, const int N, const int K, const int8_t* A,
const int8_t* B, int32_t* C) {
int i, j, k;
int32_t sum;
for (i = 0; i < M; ++i) {
for (j = 0; j < N; ++j) {
sum = 0;
for (k = 0; k < K; ++k) {
sum += A[i * K + k] * B[k * N + j];
}
C[i * N + j] = sum;
}
}
}
RISC-V Multi-core System
OpenMPを用いた行列積カーネルの性能評価には、以下に示すRISC-Vマルチコアシステムを実装したDigilent社のFPGAボードNexys Videoを使用しました。
- プロセッサ: 2018年のRISC-V SoftCPUコンテストで1位を獲得したVexRiscvのオクタコア
- ISA: RV32IMAFDC(RV32GC)
- 動作周波数: 100 MHz
- DRAM: 512 MiB
- OS: Linux
Matrix Multiplication using OpenMP on RISC-V Multi-core
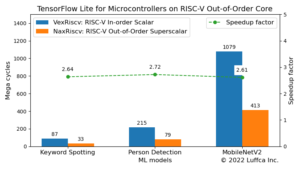
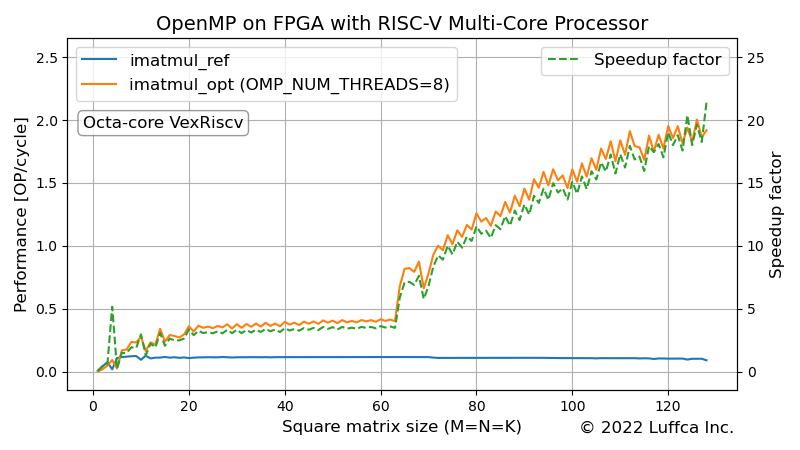
アイキャッチ画像が、OpenMPを用いた行列積カーネルimatmul_optの性能を表しています。Performance [OP/cycle]は、10回のプログラム実行の平均を用いて算出しています。
小行列では、並列化に伴うオーバーヘッドが大きく並列化の効果が低いことから、正方行列のサイズ(M=N=K)が64未満の場合、行列積カーネルをシングルスレッドで動作させています。
正方行列のサイズが32、64、128の場合、リファレンスカーネルと比較して、それぞれ3.30倍、5.89倍、21.42倍のスピードアップを実現しました。
まとめ
Luffcaでは、RISC-VマルチコアプロセッサのオクタコアVexRiscvをFPGAボードに実装し、OpenMPを用いた行列積カーネルの性能を評価しました。