TFLite Micro on RISC-V Out-of-Order Core with Custom Instructions
Luffcaでは、RISC-V Out-of-Order CoreのNaxRiscvにカスタム命令としてSIMD命令を追加し、GoogleのTensorFlow Lite for Microcontrollers(以下、TFLite Micro)の推論を高速化しました。
関連記事のTensorFlow Lite for Microcontrollers on RISC-V Out-of-Order Coreにおいて、NaxRiscvを実装したFPGAボード上で、TensorFlow LiteのベアメタルバージョンであるTFLite Microの実行に成功したことを紹介しました。この記事は、その続編です。
NaxRiscvの関連記事は、こちら。
NaxRiscv
NaxRiscvは、アウトオブオーダ実行スーパースカラのRISC-Vコアであり、SoC builderのLiteXに統合されています。NaxRiscvの概要は、関連記事のBenchmarks on RISC-V Out-of-Order Simulatorをご覧ください。
NaxRiscv Custom Instructions
NaxRiscvは、SpinalHDLというハードウェア記述言語で記述されており、SpinalHDLを用いてカスタム命令を追加することができます。NaxRiscv documentationのCustom instructionには、カスタム命令としてSimdAddを追加する例が紹介されています。
今回は、上記のSimdAddの例を参考に、カスタム命令としてSIMD命令(mul + reduction sumとその変形)を追加するためにSimdMulPlugin.scalaファイルを作成しました。NaxRiscvはプラグインにより機能を追加できるようになっており、MUL命令やDIV命令もそれぞれMulPluginやDivPluginとして実装されています。
また、カスタム命令のSIMD命令がALU0とALU1の両方で実行できるように、ALU0とALU1にSimdMulPluginを追加し、Digilent社のFPGAボードであるNexys Video用のゲートウェアを作成しました。
TFLite Micro on NaxRiscv with SimdMul
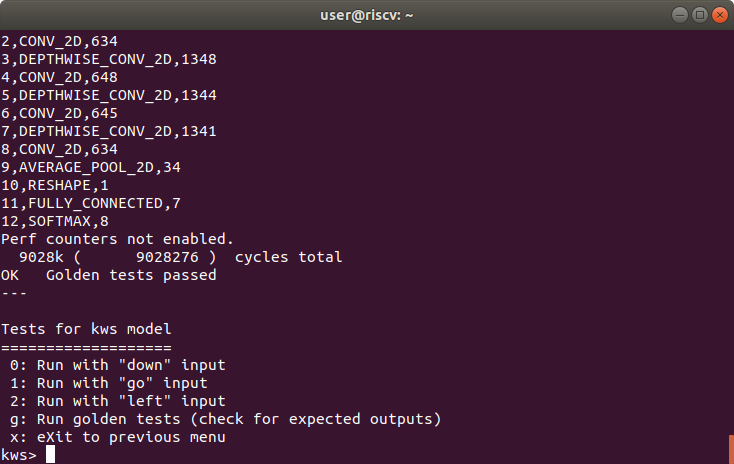
Result of golden tests for Keyword Spotting model
上記のゲートウェアをFPGAボードのNexys Videoにロードし、TFLite MicroのKeyword Spotting、Person Detection及びMobileNetV2モデルを実行しました。
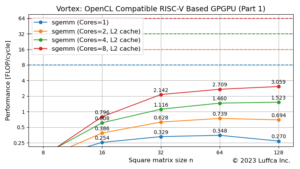
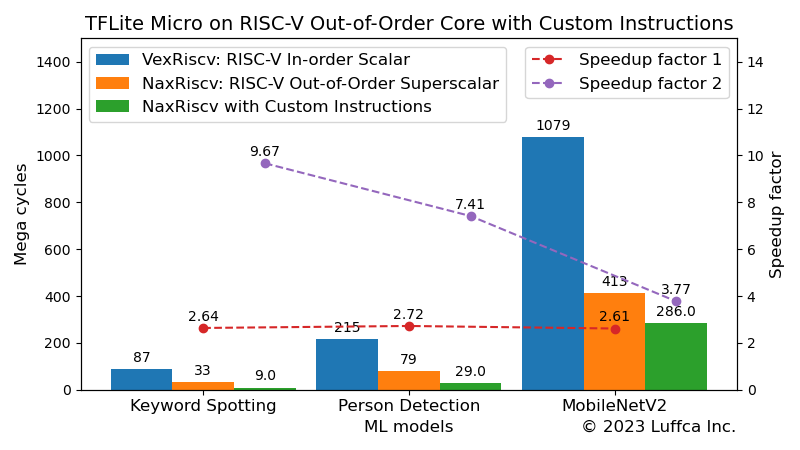
アイキャッチ画像と下の表は、インオーダ実行スカラのRISC-VコアであるVexRiscvと比較した結果を示しています。
| ML models | Mega cycles | Speedup factor |
|
|---|---|---|---|
| VexRiscv | NaxRiscv w/ SimdMul |
||
| Keyword Spotting | 87 | 9.0 | 9.67 |
| Person Detection | 215 | 29 | 7.41 |
| MobileNetV2 | 1079 | 286 | 3.77 |
Keyword Spottingモデルの推論のサイクル数は9.0Mであり、VexRiscvと比較したスピードアップは、およそ9.7倍です。Building an ML Processor using CFU Playground (Part 2)のMLプロセッサのサイクル数は9.8Mなので、同等の性能を有していることになります。
また、Person Detectionモデルの推論のサイクル数は29Mであり、VexRiscvと比較したスピードアップは、およそ7.4倍です。Applying the Tiny Matrix Extension to ML Inferenceの行列積演算を高速化するプロセッサのサイクル数は29.3Mなので、こちらも同等の性能を有していることになります。
まとめ
Luffcaでは、アウトオブオーダ実行スーパースカラのRISC-VコアであるNaxRiscvにカスタム命令としてSIMD命令を追加し、インオーダ実行スカラのRISC-VコアであるVexRiscvと比較して、TFLite MicroのKeyword Spottingモデルの推論をおよそ9.7倍高速化しました。