Vortex: OpenCL Compatible RISC-V Based GPGPU (Part 2)
この記事では、RISC-VベースのオープンソースGPGPUであるVortexのOpenCL対応について紹介します。
関連記事のVortex: OpenCL Compatible RISC-V Based GPGPU (Part 1)では、Vortexの全体像と、Vortexシミュレータを用いてテストプログラムを実行する方法を紹介しています。
Vortex
Vortexは、RISC-V ISAにGPGPUのためのカスタム命令を追加したSIMT(single instruction, multiple threads)実行モデルのGPGPUプロセッサです。Vortexの概要は、関連記事のPart 1をご覧ください。
Vortexは、OpenCL 1.2をサポートしています。この記事では、VortexのOpenCLサポートについて見てゆきます。
Software Stack for OpenCL
Vortexは、OpenCLに対応するためにオープンソース・フレームワークのPoCL(Portable Computing Language)を使用しています。OpenCL用のソフトウェアスタックとしては、PoCLコンパイラ、PoCLランタイム、及びVortexランタイムがあります。
下の図は、OpenCLカーネルのソースコードからバイナリを生成する流れを示しています。なお、PoCLコンパイラは、内部的にClang/LLVMを使用しています。
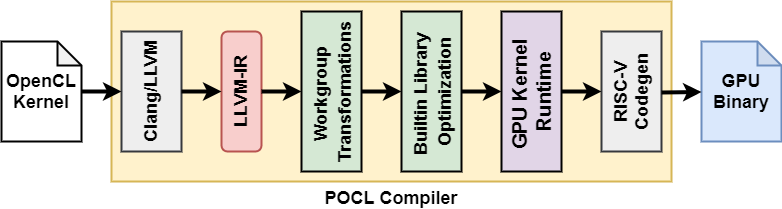
Vortex binary generation steps for OpenCL applications.
Vortexをターゲットとするカーネルプログラムを生成できるように、PoCLコンパイラが構成されていることが分かります。また、PoCLランタイムは、Vortexドライバにアクセスできるように変更されているようです。
下の図は、Vortexランタイムの構成を示しています。標準Cライブラリとして、Newlibを使用していることが分かります。
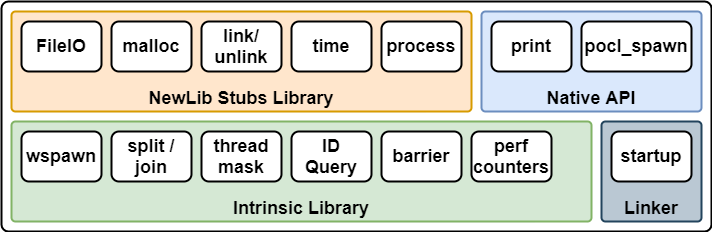
Vortex Runtime
VortexのISAはRV32IMFをベースとしていますが、カスタム命令を追加しています。既存のClang/LLVMを変更することなく、追加したカスタム命令を使用するために、VortexランタイムにIntrinsic Libraryが実装されています。
OpenCL Examples
Vortexリポジトリのtests/openclディレクトリに、OpenCLのテストプログラムがあります。OpenCLのプログラムは、ホストとデバイスのコードに分かれており、それぞれmain.[cc|cpp]とkernel.clです。
OpenCLでは、デバイス側でカーネルが並列実行されることにより、高速化を図ります。以下では、具体例としてtests/opencl/sgemmのコードを見てゆきます。なお、差異を分かりやすくするため、コードを少し変更しています。
以下は、ホストで実行されるmain.ccのmatmul関数を示しています。
void matmul(const float* A,
const float* B,
float* C,
int N) {
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
float acc = 0.0f;
for (int k = 0; k < N; ++k) {
acc += A[i + k * N] * B[k + j * N];
}
C[i + j * N] = acc;
}
}
}
以下は、上記関数に対応するデバイスで実行されるkernel.clを示しています。
__kernel void sgemm(__global const float* A,
__global const float* B,
__global float* C,
int N) {
const int i = get_global_id(0);
const int j = get_global_id(1);
float acc = 0.0f;
for (int k = 0; k < N; ++k) {
acc += A[i + k * N] * B[k + j * N];
}
C[i + j * N] = acc;
}
kernel.clでは、matmul関数のiとjに関するループが削除されています。その代わりに、各カーネルが、与えられたiとjを用いて行列Cの(i, j)成分だけを計算するように変更されています。これが、デバイス側でカーネルが並列実行されることにより、高速化を図れる仕組みです。
但し並列化だけだと、Global Memoryに対するレイテンシの大きさが顕在化してくるのため、実際にはレイテンシの小さいPrivate MemoryやLocal Memoryを使用する例が多く見られます。しかし、VortexにおけるLocal Memoryの使用に関しては、リポジトリにLocal memory issue #10が上がっています。
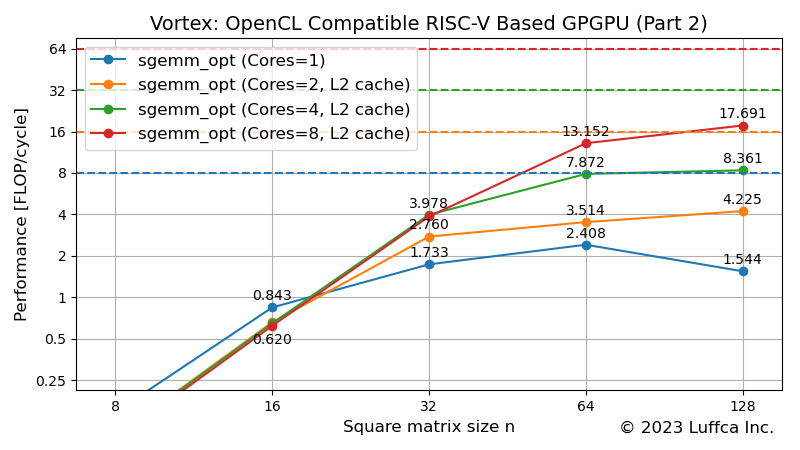
Part 1で紹介したVortexのsgemmの効率を分析してみます。スレッド数のデフォルト値は4のため、クアッドコア構成では同時に16スレッドが動作していることになります。行列サイズ128におけるPerformance(FLOP/cycle)は1.528であり、その効率は5%以下(1.528/(2*16)*100)です。
Running sgemm_opt on Vortex RTL Simulator
あまりに効率が悪いため、Local Memory以外の方法を用いて、sgemmの効率を向上させてみました。
具体的には、OpenCLのPrivate Memoryに相当するVortexのレジスタファイルを利用して4×4のブロック化を行うと共に、ループのアンローリングを行いました。また、コンパイラがFMA(fmadd.s)ではなくfmul.sとfadd.sに変換していたため、FMAマクロを追加しています。
アイキャッチ画像は、効率を向上させたsgemm_optの結果を示しています。クアッドコア構成の場合、行列サイズ128におけるPerformance(FLOP/cycle)は8.361であり、最適化によってPerformanceが約5倍向上しました。また、その効率は約26%(8.361/(2*16)*100)です。64-bit Rocket ChipのFPGA実装とOpenBLASの組み合わせでも、SGEMMの効率は20%を下回るので、GPGPUらしい性能になって来ました。
まとめ
この記事では、RISC-VベースのオープンソースGPGPUであるVortexのOpenCL対応について紹介しました。また、プログラムの変更によって、sgemmの効率が5%以下から約26%に改善できることを確認しました。