Building an ML Processor using CFU Playground (Part 1)
Luffcaでは、CFU Playgroundを用いて、Arty A7-35T上にML(Machine Learning)プロセッサを作成しました。パート1では、Person Detection int8モデルの推論を5.6倍高速化しました。
関連記事は、こちら。
- パート1: Person Detection int8モデル(本記事)
- パート2: Keyword Spottingモデル
- パート3: MobileNetV2モデル
注:パート3の成果を反映し、2022/8/21にパート1の内容を更新しました。
CFU Playground
CFU Playgroundは、GoogleのTFLM(TensorFlow Lite for Microcontrollers)のMLモデルを高速化するために、ハードウェア(実際には、FPGAのゲートウェア)とソフトウェアをチューニングするためのフレームワークです。
cfu-playground.readthedocs.ioから引用した下図は、CFU Playgroundの概要を示しています。
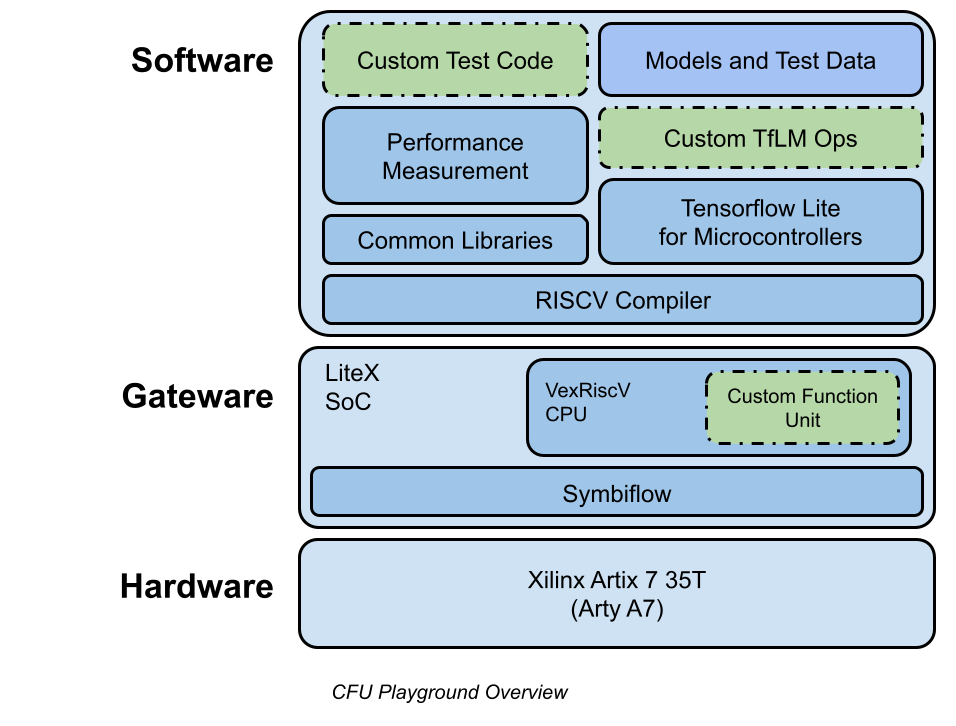
CFU Playgroundでは、MLモデルの推論を高速化のために、RISC-Vのカスタム命令を利用します。
カスタム命令に対応するハードウェアを追加するために、RISC-V 32-bit ソフトCPUのVexRiscvとSoCビルダーのLiteXの組み合わせによって実現されているCFU(Custom Function Unit)と呼ばれる機能を使用しています。
具体的には、Amaranth HDL(以前のnMigen)を利用してPythonのコードからcfu.vを生成し、それをVexRiscvおよびLiteXのVerilogファイルと組み合わせてゲートウェアを作成します。cfu.vを直接作成してゲートウェアを作成することもできます。
ソフトウェア面では、#include "cfu.h"により、TFLM内でカスタム命令cfu_op(funct3, funct7, rs1, rs2)が使用できるようになります。
また、パフォーマンスカウンタによって特定の処理のサイクル数を計測する仕組みがあります。但し、リソースに制限があるFPGAボードでは利用できない場合があるようです。
Person Detection int8 Model
CFU Playgroundにおいてpdti8と呼ばれているPerson Detection int8モデルは、The Step-by-Step Guide to Building an ML Accelerator(以下Guide)でも取り上げられているモデルです。
このモデルは、各14層のCONV_2DとDEPTHWISE_CONV_2D(以下dw_conv)と、各1層のAVERAGE_POOL_2D、RESHAPE、SOFTMAXの合計31層のモデルです。
このモデルのCONV_2Dは、実際には、1×1 convolution(以下1x1_conv)として動作しています。
Building an ML Processor
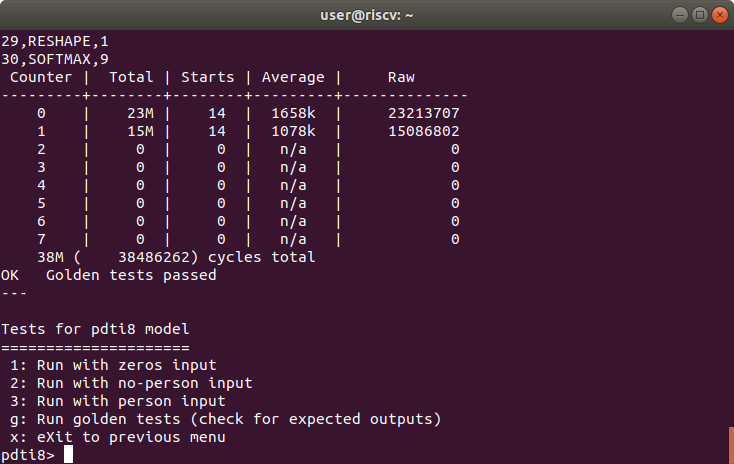
Result of golden tests for pdti8 model
Guideでは、高速化の対象が1x1_convだけですが、今回はdw_convも対象にしました。
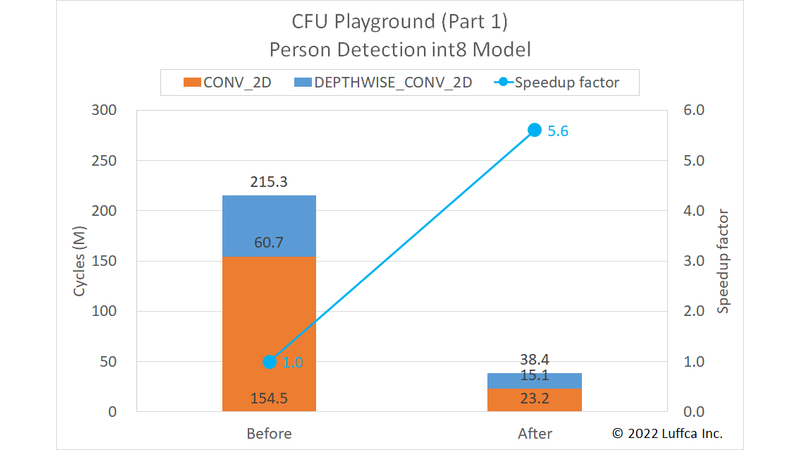
先に結果を紹介すると、アイキャッチ画像と下の表に示すようにpdti8モデルの全サイクル数を215.3Mから38.4Mに高速化できました。
| Person Detection int8 Model | Cycles | Speedup factor |
|
|---|---|---|---|
| Before | After | ||
1x1_conv |
154.5M | 23.2M | 6.7 |
dw_conv |
60.7M | 15.1M | 4.0 |
| Total | 215.3M | 38.4M | 5.6 |
Guideでは、高速化後の全サイクル数が86Mなので、これと比較すると、かなり高速化できたと思います。
また、pdti8モデルを高速化している上記GitHubのproj/avg_pdti8を以前にベンチマークしたときは、全サイクル数が67Mだったので、dw_convの高速化が結果に寄与していると考えています。
Software Specialization
Guideにも記載されているように、ソフトウェアの専用化は、MLモデルの高速化に効果的です。
CONV_2DのConvPerChannel関数は、以下のようになっています。
for (int batch = 0; batch < batches; ++batch) {
for (int out_y = 0; out_y < output_height; ++out_y) {
const int in_y_origin = (out_y * stride_height) - pad_height;
for (int out_x = 0; out_x < output_width; ++out_x) {
const int in_x_origin = (out_x * stride_width) - pad_width;
for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
int32_t acc = 0;
for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
const int in_y = in_y_origin + dilation_height_factor * filter_y;
for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
const int in_x = in_x_origin + dilation_width_factor * filter_x;
// Zero padding by omitting the areas outside the image.
const bool is_point_inside_image =
(in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
(in_y < input_height);
if (!is_point_inside_image) {
continue;
}
for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
...
フィルタサイズが1×1専用のConvPerChannel1x1関数では、ループや変数の省略が可能になり、is_point_inside_imageの計算も必要なくなって、以下のようにシンプルなコードになります。
for (int batch = 0; batch < batches; ++batch) {
for (int y = 0; y < output_height; ++y) {
for (int x = 0; x < output_width; ++x) {
for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
int32_t acc = 0;
for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
...
CFU Optimization
CFUによる最適化の例として、Guideでも紹介されているSIMD MAC(multiply-accumulate)のカスタム命令は、以下のような入出力となります。
int8_t int8_t int8_t int8_t
+----------------+----------------+----------------+----------------+
in0 = | input_data[0] | input_data[1] | input_data[2] | input_data[3] |
+----------------+----------------+----------------+----------------+
int8_t int8_t int8_t int8_t
+----------------+----------------+----------------+----------------+
in1 = | filter_data[0] | filter_data[1] | filter_data[2] | filter_data[3] |
+----------------+----------------+----------------+----------------+
int32_t
+-------------------------------------------------------------------+
output = | output + (input_data[0, 1, 2, 3] + 128) * filter_data[0, 1, 2, 3] |
+-------------------------------------------------------------------+
なお、funct3とfunct7は、それぞれ2と1に割り付けました。
オリジナルのConvPerChannel関数のインナーループは、以下のようになっています。
for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
int32_t input_val = input_data[Offset(
input_shape, batch, in_y, in_x, in_channel)];
int32_t filter_val = filter_data[Offset(
filter_shape, out_channel, filter_y, filter_x, in_channel)];
acc += filter_val * (input_val + input_offset);
}
上記に対応する1x1_conv専用のConvPerChannel1x1関数のインナーループは、以下のようになります。
for (int in_channel = 0; in_channel < input_depth; in_channel += 4) {
uint32_t input_val_4 = *((uint32_t*)(input_data + Offset(
input_shape, batch, y, x, in_channel)));
uint32_t filter_val_4 = *((uint32_t*)(filter_data + Offset(
filter_shape, out_channel, 0, 0, in_channel)));
acc = cfu_op2(1, input_val_4, filter_val_4);
}
1x1_convの場合、TFLMはチャネルラストなのでint8_tのinput_dataとfilter_dataは、それぞれ連続してアクセスできます。
まとめ
Luffcaでは、CFU Playgroundを用いて、Arty A7-35T上にMLプロセッサを作成しました。作成したMLプロセッサは、Person Detection int8モデルの推論を38.4Mサイクルで実行できます。