Building an ML Processor using CFU Playground (Part 2)
Luffcaでは、CFU Playgroundを用いて、Arty A7-35T上にML(Machine Learning)プロセッサを作成しました。パート2では、Keyword Spottingモデルの推論を8.9倍高速化しました。
なお、CFUはCustom Function Unitの略語であり、LiteX/VexRiscvにおいてRISC-Vのカスタム命令用ハードウェアを追加する仕組みです。
関連記事は、こちら。
- パート1: Person Detection int8モデル
- パート2: Keyword Spottingモデル(本記事)
注:パート3の成果を反映し、2022/8/21にパート2の内容を更新しました。
CFU Playground
CFU Playgroundは、GoogleのTFLM(TensorFlow Lite for Microcontrollers, tflite-micro)のMLモデルを高速化するために、ハードウェア(実際には、FPGAのゲートウェア)とソフトウェアをチューニングするためのフレームワークです。
詳細は、パート1の記事をご覧ください。
Keyword Spotting Model
CFU Playgroundにおいてkwsと呼ばれているKeyword Spottingモデルは、MLPerf Tiny Deep Learning BenchmarksからTFLMに追加されたモデルの一つです。
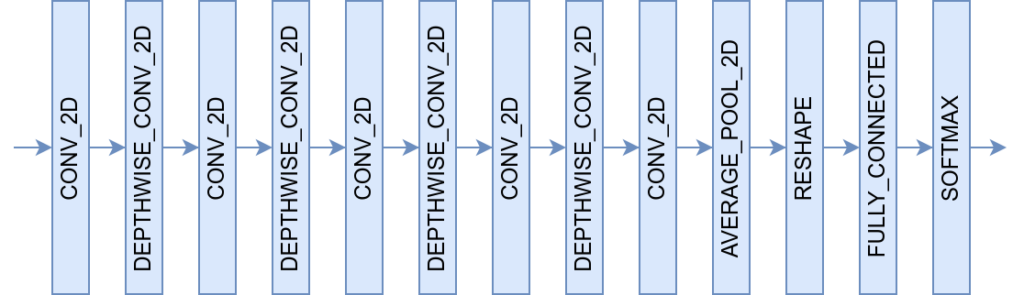
下図に示すように、このモデルは、5層のCONV_2D、4層のDEPTHWISE_CONV_2D(以下dw_conv)等から構成される全13層のモデルです。
このモデルの第3層以降のCONV_2Dは、1×1 convolution(以下1x1_conv)として動作します。
multimodel_accel project
Result of golden tests for kws model
multimodel_accelプロジェクトは、CFU Playgroundのほとんどのプロジェクトが一つのMLモデルに限定して高速化するモデル特化を行っているのに対し、複数のMLモデルを高速化することを目標とする社内プロジェクトです。
上記の背景として、CFU Playgroundのkws_micro_accelプロジェクトでは、kwsモデルに特化されているため、パート1の記事で紹介したPerson Detection int8(以下pdti8)モデル等の他モデルに対しては、高速化の効果がありません。
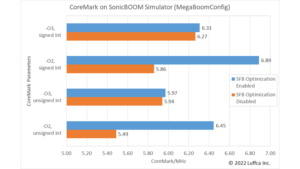
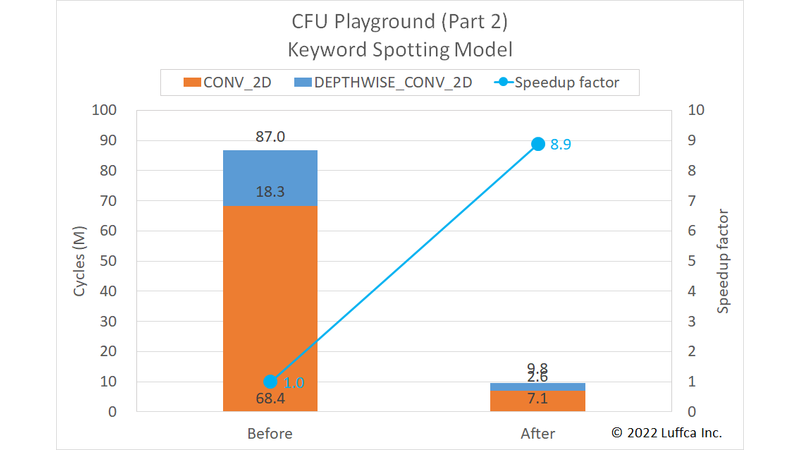
先に結果を紹介すると、アイキャッチ画像と下の表に示すようにkwsモデルの全サイクル数が87.0Mから9.8Mに減少し、8.9倍の高速化を達成しました。
| Keyword Spotting Model | Cycles | Speedup factor |
|
|---|---|---|---|
| Before | After | ||
CONV_2D |
68.4M | 7.1M | 9.6 |
DEPTHWISE_CONV_2D |
18.3M | 2.6M | 7.2 |
| Total | 87.0M | 9.8M | 8.9 |
Arty A7-35T用ゲートウェアの動作周波数は100MHzのため、レイテンシは98msとなります。
MLPerf Tiny v0.5 inference benchmarksにおける動作周波数120MHzのArm Cortex-M4のレイテンシが181.92msなので、上記の結果は単純比較でも1.8倍高速であり、動作周波数を正規化すると2.2倍高速ということになります。
Software Specialization & CFU Optimization
multimodel_accelプロジェクトでは、kwsモデルとpdti8モデルの両方に適用できるように特化・最適化した1x1_convとdw_convを使用しています。
但し、他の層の高速化に伴いkwsモデルの第1層の処理時間の比率が高くなってきたため、kwsモデルの第1層に特化したkws_convを追加しています。
全31層のpdti8モデルでは、第1層は特化も最適化も行っていないのですが、全13層のkwsモデルでは、第1層の影響が強く出る傾向にあります。
まとめ
Luffcaでは、CFU Playgroundを用いて、Arty A7-35T上にMLプロセッサを作成しました。作成したMLプロセッサは、Keyword Spottingモデルの推論を8.9倍高速化し、9.8Mサイクルで実行できます。