Matrix Multiplication on FPGA with the RISC-V Vector Extension
Luffcaでは、RISC-Vベクトル拡張(Vector Extention)のVicunaをFPGAボードに実装し、行列積カーネルの性能を評価しました。
関連記事は、こちら。
- Running Auto-Vectorized Program on RISC-V Vector RTL Simulator
- Matrix Multiplication based on the RISC-V Vector Extension
- 1×1 Convolution based on the RISC-V Vector Extension
- Matrix Multiplication on FPGA with the RISC-V Vector Extension(本記事)
Vicuna
Vicunaは、SystemVerilogで記述された32-bit integer vector coprocessorです。具体的には、8, 16, 32-bit整数だけをサポートし、64-bit整数や浮動小数点数のサポートを必要としないRISC-Vベクトル拡張のZve32xに準拠してしています。ただし、記事執筆時点では除算系の命令が欠けています。
Vicunaはコプロセッサのため、メインプロセッサのIbexまたはCV32E40Xを必要とします。
FPGA with Vicuna
今回は、Digilent社のFPGAボードのNexys Video用ゲートウェアを作成しました。
Nexys Video用ゲートウェアの主な仕様は、以下の通りです。
- Processor
- メインプロセッサ: Ibex
- コプロセッサ: Vicuna
- VLEN(ベクトルレジスタのビット長): 512-bit
- 乗算器のビット長: 256-bit
- ISA: RV32IMCV
- 動作周波数: 100 MHz
- SRAM: 256 KiB
- UART: 1 ch
Matrix Multiplication on FPGA with Vicuna
行列積のリファレンス・カーネルには、以下のコードを使用しました。
// C = AB with A = [M x K], B = [K x N], C = [M x N]
void imatmul_ref(const int M, const int N, const int K, const int32_t* A,
const int32_t* B, int32_t* C) {
int i, j, k;
int32_t sum;
for (i = 0; i < M; ++i) {
for (j = 0; j < N; ++j) {
sum = 0;
for (k = 0; k < K; ++k) {
sum += A[i * K + k] * B[k * N + j];
}
C[i * N + j] = sum;
}
}
}
他の記事と同じように行列AとBの成分はint8_tに設定していたのですが、Vicunaのvsext.vf2の結果が正しくなかったためint32_tに変更しています。調査すると、GitHubにissueが上がっていました。
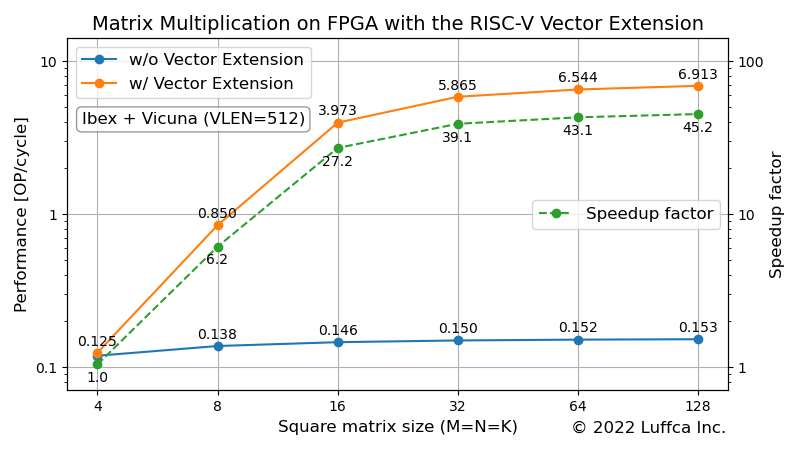
上のアイキャッチ画像が、Vicunaの性能を表しています。
正方行列のサイズ(M=N=K)が32、64、128の場合、RISC-Vベクトル拡張に基づく行列積カーネルのPerformance [OP/cycle]は、それぞれ5.865、6.544、6.913であり、リファレンス・カーネルと比較して、39〜45倍のスピードアップを実現しています。
まとめ
Luffcaでは、RISC-Vベクトル拡張のZve32xに準拠したVicunaをFPGAボードに実装し、行列積カーネルの性能を評価しました。