GEMM based on the RISC-V Vector Extension (Part 2)
RISC-Vベクトル拡張に基づく浮動小数点行列積カーネルについて、数回に渡ってお伝えしていきます。Part 2では、転置行列対応のためにAraのRTLシミュレータを用いてベクトル ロード/ストア性能を評価しました。
関連記事のGEMM based on the RISC-V Vector Extension (Part 1)では、任意の行列サイズに対応した倍精度、単精度及び半精度浮動小数点行列積カーネルの性能を評価しています。
Vector Loads and Stores
RISC-Vベクトル拡張には、ベクトル レジスタとメモリとの間で値を移動するために下記のベクトル ロード/ストア命令があります。
- ベクトル ユニットストライド命令(Vector Unit-Stride Instructions)
- ベクトル ストライド命令(Vector Strided Instructions)
- ベクトル インデックス命令(Vector Indexed Instructions)
- ベクトル ユニットストライド Fault-Only-First ロード命令(Vector Unit-Stride Fault-Only-First Loads)
- ベクトル ロード/ストア セグメント命令(Vector Load/Store Segment Instructions)
この記事では、連続アクセス用のベクトル ユニットストライド命令とストライド アクセス用のベクトル ストライド命令について説明します。
Vector Unit-Stride Instructions
ベクトル ユニットストライド命令は、メモリ上の連続するデータとベクトル レジスタとの間でデータを移動します。
# Vector unit-stride loads and stores # vd destination, rs1 base address, vm is mask encoding (v0.t or <missing>) vle8.v vd, (rs1), vm # 8-bit unit-stride load vle16.v vd, (rs1), vm # 16-bit unit-stride load vle32.v vd, (rs1), vm # 32-bit unit-stride load vle64.v vd, (rs1), vm # 64-bit unit-stride load # vs store data, rs1 base address, vm is mask encoding (v0.t or <missing>) vse8.v vs, (rs1), vm # 8-bit unit-stride store vse16.v vs, (rs1), vm # 16-bit unit-stride store vse32.v vs, (rs1), vm # 32-bit unit-stride store vse64.v vs, (rs1), vm # 64-bit unit-stride store
以下の例では、アドレスaから連続するvl個の32-bitデータが、ベクトル レジスタのv0とv1にロードされます。
float* a;
asm volatile("vsetvli %0, %1, e32, m2, ta, ma" : "=r"(vl) : "r"(n));
asm volatile("vle32.v v0, (%0)" ::"r"(a));
Vector Strided Instructions
ベクトル ストライド命令は、メモリ上の一定間隔のデータとベクトル レジスタとの間でデータを移動します。
# Vector strided loads and stores # vd destination, rs1 base address, rs2 byte stride vlse8.v vd, (rs1), rs2, vm # 8-bit strided load vlse16.v vd, (rs1), rs2, vm # 16-bit strided load vlse32.v vd, (rs1), rs2, vm # 32-bit strided load vlse64.v vd, (rs1), rs2, vm # 64-bit strided load # vs store data, rs1 base address, rs2 byte stride vsse8.v vs, (rs1), rs2, vm # 8-bit strided store vsse16.v vs, (rs1), rs2, vm # 16-bit strided store vsse32.v vs, (rs1), rs2, vm # 32-bit strided store vsse64.v vs, (rs1), rs2, vm # 64-bit strided store
以下の例では、アドレスaから間隔nのvl個の32-bitデータが、ベクトル レジスタのv0とv1にロードされます。
float* a;
asm volatile("vsetvli %0, %1, e32, m2, ta, ma" : "=r"(vl) : "r"(m));
asm volatile("vlse32.v v0, (%0), %1" ::"r"(a), "r"(n * sizeof(float)));
Vector Load/Store on Ara RTL Simulator
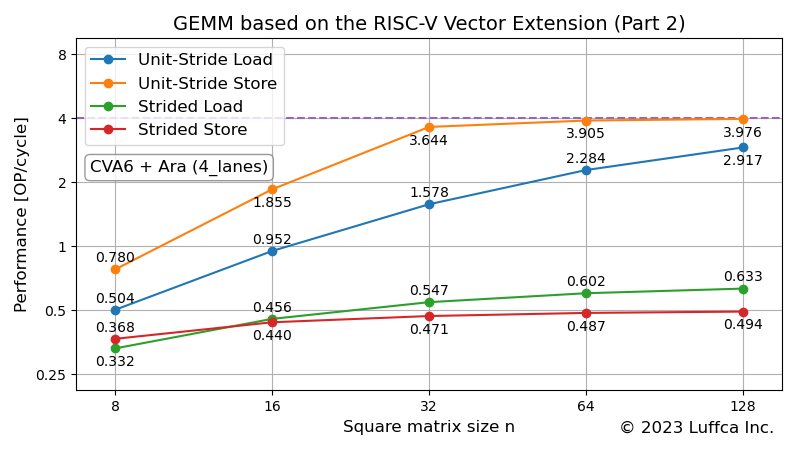
アイキャッチ画像は、AraのRTLシミュレータの4_lanes構成における32-bitのユニットストライド ロード/ストア(vle32.vとvse32.v)とストライド ロード/ストア(vlse32.vとvsse32.v)の性能を表しています。
なお、Araの4_lanes構成のAXIデータ幅は128-bitなので、32-bitデータに対するルーフラインは4です。
ユニットストライド ロード/ストアの性能がルーフラインに漸近しているのに対し、ストライド ロード/ストアの性能が低いことがわかります。正方行列サイズが128とき、ストライド ロード/ストアは、ユニットストライド ロード/ストアのそれぞれ約1/4と約1/8の性能です。
GEMM transposed matrix support
ここでは、GEMM(GEneral Matrix-to-matrix Multiply)の転置行列対応について検討します。
GEMMの転置行列対応においては、ベクトル ロード命令をユニットストライド ロードからストライド ロードに切り替えることが一番簡単な方法ですが、大幅に性能が低下します。ベクトル ロード命令は、GEMMの最内ループで使用されており、ユニットストライド ロードよりも性能が低いストライド ロードに切り替えると、これまで隠蔽されていたメモリアクセスが顕在化して、サイクル数に影響を与えるようです。
今回は、行列Bの転置が必要な場合、予め転置した行列BTを作成し、GEMMの最内ループでは、行列BTに対してユニットストライド ロードを行う方法を選択しました。これにより、GEMMの最内ループの性能は低下せず、ストライド アクセスの使用は、行列BTの作成時のみとなります。
ベクトル ロード/ストア命令を用いて行列BTを作成するには、以下の二つの方式が考えられます。
- 方式1: ユニットストライド ロード後にストライド ストア
- 方式2: ストライド ロード後にユニットストライド ストア
アイキャッチ画像に示された個々の性能に基づいて二つの方式を比較すると、方式2の方が性能が高く、実測でも同じ結果が得られました。正方行列サイズnが128とき、単精度浮動小数点の行列BTを作成するためのサイクル数は、およそ30k(≈2n2)です。
なお、プロセッサのCVA6を用いて行列BTを作成することもできますが、方式2の約1/4の性能です。
まとめ
Luffcaでは、RISC-Vベクトル拡張に基づく浮動小数点行列積カーネルの転置行列対応のために、AraのRTLシミュレータを用いてベクトル ロード/ストア性能を評価しました。
Araでは、連続アクセスと比較して、ストライド アクセスの性能が低いことが分かりました。行列Bの転置を必要とする場合、ストライド アクセスの使用回数を減らすため、予め転置した行列BTを作成する方法を選択しました。